Nuevas equivalencias (y diferencias) en los paquetes DBI y Dplyr en R (1)
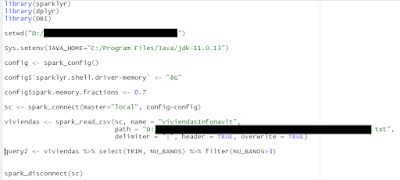
Parece ser que es complicado el manipular una colección de datos que regresa una consulta realizada usando el paquete dplyr junto con Apache Spark , al decir complicado, me refiero a que no podemos manipularlo al igual que un dataframe que tiene características muy parecidas a una tabla o colección de otro lenguaje de programación. Me clavé en una investigación que me llevó algunas horas (2 o 3) y aunque todavía no encuentro algo concluyente parece ser que no es posible traer los elementos individuales de dicha colección, pareciera que es debido al gran tamaño que pueden tener. La siguiente información viene del sitio " RDD Programming Guide - Spark 3.3.0 Documentation " que documenta las acciones que se tienen para manipular estos datasets y según comparándola con otra bibliografía collect() transforma el RDD en un objeto de R para nuestro caso. " collect() - Regresa todos los elementos del dataset como un arreglo en el controlador (driver) del programa. Esto es