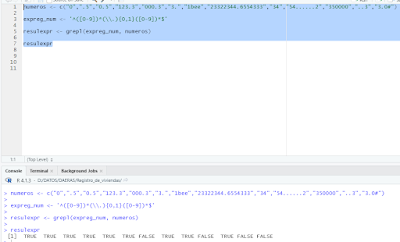
Mas sobre apply
Una cosa importante es el poder implementar funciones propias usando apply, el investigar diversos caminos puede ser que al final el que creíamos que sería el idóneo, no lo es. Sin embargo el conocimiento queda ahí para futuras soluciones. Vamos ahora a ver como crear nuestras propias funciones y que se ejecuten en un apply . Tenemos el siguiente fragmento del script: library(tidyverse) df <- as.data.frame(read_csv("ruta/2008.csv",n_max = 100000)) df2 <- df[,c("CarrierDelay","WeatherDelay", "NASDelay", "SecurityDelay", "LateAircraftDelay")] df_clean <- df2[complete.cases(df2),] Una nueva función es complete.cases que elimina aquellos registros que tengan valores "ausentes" (missing - NA). > nrow(df_clean) [1] 19627 >