En los primeros cursos de R, me llamaba la atención de como utilizar herramientas para las consultas a los datos, algún símil de lo que hace SQL, o lo que se hace usando los menús de SPSS, STATA o REDATAM.
En mi anterior área donde hay más informáticos que matemáticos lo que hacíamos era que el motor dejara los conjuntos de datos listos para que R procesara - en nuestro caso - los cálculos usando el paquete estadístico survey ya que estábamos en el ámbito de las encuestas.
En este caso donde la mayoría de mis compañeros son matemáticos, R es el estandarte y en estos días de aprendizaje no lo hace nada mal.
Una de las cosas por las que me fui en esta ocasión por R es tratar de ponerme al corriente con mis compañeros porque bien lo pude haber hecho en otro lenguaje o motor de base de datos pero es necesario ya conocer o hacer lo que puedo con otras herramientas, ahora con R.
También algo genial es la velocidad con la que se cargan los archivos para el caso de objetos de Spark, pero esto lo abordaré en otro post.
Lo que buscaba era hacer comparativo de puestos de trabajo que reporta el IMSS en su sitio de datos abiertos, el archivo que se descarga consta de más de 4 millones de registros.
Como bien saben para hacer este tipo de estudios es necesario conocer de menos el diccionario de datos o lo que gracias a nuestro lenguaje ancestral de programación COBOL, le llamamos FD (File Description) para saber como se obtienen las cifras ya que debido al país que es México, 4 millones de empleos hablando de períodos de referencia mensuales no son suficientes para satisfacer la demanda de la población económicamente activa.
Para este ejercicio usé los puestos de trabajo como referencia al 31 de agosto del 2017 archivo que se encuentra en la siguiente dirección y el diccionario de datos en este enlace.
Los archivos de datos son CSV y un archivo de MS Excel es el diccionario de datos. Para empezar tenemos que cargar los datos y debido a la extensión de los mismos, reitero que usar Spark es increible la velocidad conque se cargan los datos a su dataset, para los colegas de TICs es muy buena opción el instalar también el paquete DBI que permite hacer consultas estilo SQL.
Entonces primero cargamos las librerías y con ellas el archivo.
library("sparklyr")
library("dplyr")
library("DBI")
setwd("rutadetrabajo/")
sc <- spark_connect(master = "local")
imss201708 <- spark_read_csv(sc, name = "imss201708",
path = "rutatrabajo/asg-2017-08-31.csv",
delimiter = "|", header=TRUE, overwrite=TRUE)
Como se trata de un archivo CSV se usa spark_read_csv, el delimitador es un padline (|), los archivos tienen cabecero y en caso de que ya exista el objeto Spark, se sobreescriba.
Hice mi primer prueba de tiempo y los 4 millones de registros los cargo en 24 segundos!!
Y aquí surge nuestra primera inquietud. ¿Cuántos registros (tuplas) tiene este dataset?. Los informáticos decimos que un select count(*) from tabla.
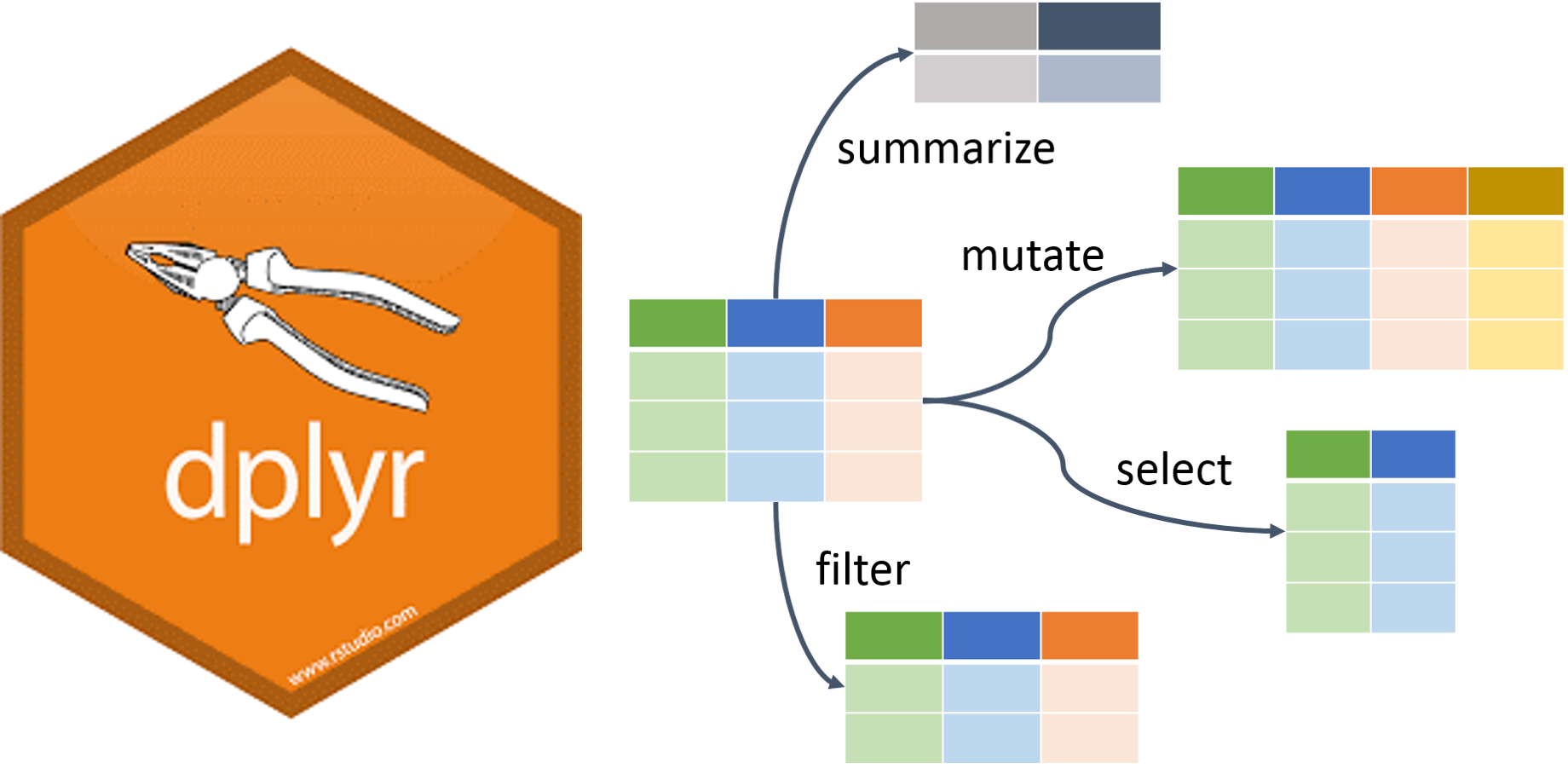
Para R o específicamente dplyr usamos estás 2 formas:
count(imss201708)
n <- imss201708 %>% summarise(n())
En SQL usando el paquete DBI (el cual se tiene que instalar previamente) la instrucción sería:
nsql <- dbGetQuery(sc, "select count(*) from imss201708")
Que nos da como resultado 4,592,365, o sea que no son 4 millones sino 4.5 millones para ser exactos.
Revisando la información del diccionario de datos ( y usando un poco de intuición) para calcular el número de puestos de trabajo asegurados al IMSS hay que sumar el contenido de una columna la cual es asegurados (como el factor de expansión en una encuesta).
Nuevamente usamos el verbo summarise de dplyr pero ponemos el nombre de la columna.
puestos_trab_total <- imss201708 %>% summarise(ptos_trab_total=sum(asegurados, na.rm = TRUE))
En SQL sería:
puestos_trab_total_sql <- dbGetQuery(sc, "select sum(asegurados) from imss201708")
Ahora la solicitud era que ahora esta información se desplegará por entidad federativa, para lo cual vamos a agregar dos verbos más que son group_by y arrange, este último lo agregué ya que la consulta salía desordenada.
puestos_trab_por_ent <- imss201708 %>% group_by(cve_entidad) %>% summarise(aseg=sum(asegurados, na.rm = TRUE)) %>% arrange(cve_entidad)
SQL
puestos_trab_por_ent_sql <- dbGetQuery(sc, "select sum(asegurados) from imss201708 group by cve_entidad")

Comentarios
Publicar un comentario