En el Instituto se utiliza como herramienta de trabajo institucional la suite de ofimática MS Office que ofrece un precio asequible aunque lo actual en el mundo del software es el esquema de suscripciones el que casi se ha convertido en el común de las empresas gigantes de las tecnologías de la información.
Es por ello que si bien en un principio que se usaban las bibliotecas XLConnectJars y XLConnect, al tratar de bajarlas e instalarlas se descubrió - en aquel entonces - que estaban obsoletas. Es por ello que se volteo a la que revisaremos superficialmente en este artículo.
Lo primero como siempre es descargar la librería openxlsx que se puede hacer desde el mismo Posit RStudio.
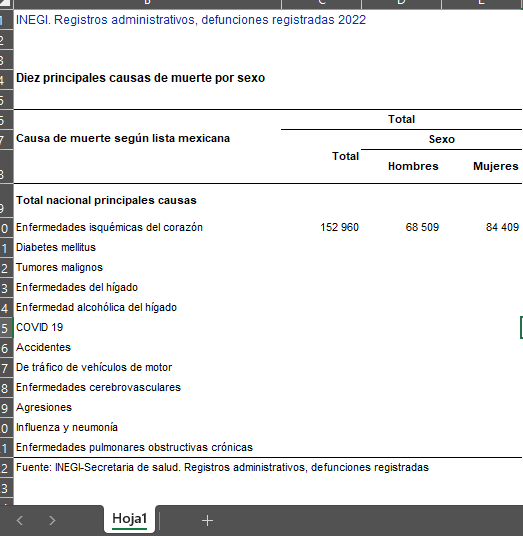
Vamos a recrear un cuadro existente en el sitio del Instituto que debido a la crisis sanitaria iniciada en 2020 cobra una relevancia muy importante: "Las principales causas de muerte" que de forma anecdótica fue la primera aplicación en la cual me pidieron que participara, un programa escrito en C que calculaba las principales causas de muerte en base a la información que se capturaba y procesaba en el "Equipo grande" (minicomputadoras o mainframes de mediados de los 90s), esto ya se hacía en equipos de escritorio personales, en aquellos tiempos empezaba la interacción entre estos 2 paradigmas del cómputo empresarial-organizacional, en aquellos tiempos la información la descargaba a la computadora usando una lectora de cintas.
Ahora es uno de los principales cuadros que presenta las notas técnicas que se publican año con año, como se puede observar en la figura siguiente:
Por lo que vamos a proceder a tratar de recrear este cuadro para el año que se tiene información que es el 2022.
Primero vamos a hacerlo de la forma más sencilla que sería calcular dato por dato cada causa. Al ser un archivo de no más de 1 millón de registros podemos hacer la lectura del archivo con read.csv().
#Método largo para obtener las 10 principales causas de muerte
library(dplyr)
library(openxlsx)
library(stringr)
setwd("Ruta")
dfMorta22 <- read.csv("conjunto_de_datos_defunciones_registradas_2022.CSV")
A continuación se hacen los cálculos para cada celda por cada causa de muerte total, así como hombres y mujeres. Dos cosas interesantes son que se observan es que la columna gr_lismex tiene un espacio en blanco, por lo cual en la condición se toma en cuenta dicho blanco. Otra curiosidad es que podemos poner dos verbos filter() y la instrucción dplyr sigue funcionando.
# Enfermedades isquémicas del corazón.
totenfisq <- dfMorta22 %>% filter(gr_lismex == ' 28') %>% tally()
totenfisq_h <- dfMorta22 %>% filter(gr_lismex == ' 28') %>%
filter(sexo == 1) %>% tally()
totenfisq_m <- dfMorta22 %>% filter(gr_lismex == ' 28' & sexo == 2) %>%
tally()
# Diabetes mellitus
totdb <- dfMorta22 %>% filter(lista_mex == '20D') %>% tally()
totdb_m <- dfMorta22 %>% filter(lista_mex == '20D') %>%
filter(sexo == 2) %>% tally()
totdb_h <- dfMorta22 %>% filter(lista_mex == '20D' & sexo == 1) %>%
tally()
#Tumores malignos
tottm <- dfMorta22 %>% filter(gr_lismex == ' 08' |
gr_lismex == ' 09' |
gr_lismex == ' 10' |
gr_lismex == ' 11' |
gr_lismex == ' 12' |
gr_lismex == ' 13' |
gr_lismex == ' 14' |
gr_lismex == ' 15') %>% tally()
tottmh <- dfMorta22 %>% filter((gr_lismex == ' 08' |
gr_lismex == ' 09' |
gr_lismex == ' 10' |
gr_lismex == ' 11' |
gr_lismex == ' 12' |
gr_lismex == ' 13' |
gr_lismex == ' 14' |
gr_lismex == ' 15') & sexo==1) %>% tally()
tottmm <- dfMorta22 %>% filter((gr_lismex == ' 08' |
gr_lismex == ' 09' |
gr_lismex == ' 10' |
gr_lismex == ' 11' |
gr_lismex == ' 12' |
gr_lismex == ' 13' |
gr_lismex == ' 14' |
gr_lismex == ' 15') & sexo==2) %>% tally()
Otra cuestión es que al manejar valores alfabéticos las instrucciones o expresiones lógicas se tornan muy extensas a que si las convertimos en números podemos manejar rangos (aunque es cierto que a veces gracias al valor ASCII también se pueden manejar rangos, al menos en lenguajes del pasado). Debido a ustedes podemos usar el verbo mutate() para crear una nueva variable sin el espacio y hacer la consulta de acuerdo al rango.
#Crear una nueva variable en un dataframe usando el verbo mutate (dplyr)
#Vamos a usar una función de cadena (letras, números, caracteres)
#str_sub
dfMorta22 <- dfMorta22 %>% mutate(gr_lismexn = str_sub(gr_lismex,2,3))
tottm <- dfMorta22 %>% filter(as.numeric(gr_lismexn)>=8 &
as.numeric(gr_lismexn)<=15) %>% tally()
Salida:
...msg <- paste("Ambos métodos dan la misma cifra", as.character(tottm),
+ as.character(tottm2), sep=" ")
>
> if(tottm==tottm2){
+ print(msg)
+ }
[1] "Ambos métodos dan la misma cifra 89574 89574"
|
|
|
A manera y para ejemplificar este ejercicio (además de explicar la biblioteca openxlsx) construimos una hoja de cálculo con el formato del cuadro siguiendo las recomendaciones para los cuadros que pública el Instituto.
Lo que sigue es vaciar las variables en las celdas de Excel y para ello se tiene que abrir el libro y al existir como un objeto ya en R se pueden escribir los valores.
repor_1 <- loadWorkbook(file = "Cuadro1.xlsx", isUnzipped = F)
writeData(repor_1, "Hoja1", totenfisq[[1]], startRow = 10, startCol = 'C', rowNames = F)
writeData(repor_1, "Hoja1", totenfisq_m[[1]], startRow = 10, startCol = 'D', rowNames = F)
writeData(repor_1, "Hoja1", totenfisq_h[[1]], startRow = 10, startCol = 'E', rowNames = F)
saveWorkbook(repor_1, "Cuadro1.xlsx", overwrite = T)
En repor1 se carga el libro de MS Excel, en las primeras pruebas algo que me fallaba era que omitía o ponía el valor T (True-verdadero) en el parámetro isUnzipped que otro recuerdo que tengo es que cuando Microsoft cambio de los archivos con extensión .xls a .xlsx aparte de que eran ya archivos en algún tipo de xml, también que tenían algún tipo de compresión y por esto - creo - que el parámetro se deja en F (False-Falso). En estos últimos experimentos se abre el archivo sin problemas inclusive con versiones recientes como la que tiene el Instituto.
Teniendo ya el objeto - que es el libro - ahora vamos a mandarles los valores, y esto es usando la función writeData() donde se manda el objeto que contiene el libro, después la hoja donde vamos escribir, después el valor que vamos a insertar en la celda, para poner la coordenada se usan los parámetros startRow y startCol, que con sorpresa y no recuerdo si en las versiones pasadas lo aceptaba, que cuando referenciamos columnas, acepta letras y no solo números, lo cual ayuda mucho para colocar los valores.
Para este caso caso nos enfrentamos con un detalle al mostrar los datos, si yo imprimo el valor de una variable ocurre lo siguiente:
> totenfisq
n
1 152960
> totenfisq_h
n
1 84409
> totenfisq_m
n
1 68509
Se puede observar que salen dos valores, tal si fuera un arreglo de dos dimensiones, y al principio en la hoja aparecían tanto la "n" como cifra. Después de probar empíricamente las posibilidades de solución lllegamos a que con el uso de corchetes dobles [[]] y su índice o bien la variable junto con su operador "$" , que para este código se optó por los dobles corchetes.
> totenfisq[[1]]
[1] 152960
> totenfisq$n
[1] 152960
|
|
|
Corriendo las instrucciones arriba mostradas tenemos que aparece la hoja con estos valores.
Y bueno hasta aquí este ejemplo, ya si alguien desea completarlo como ejercicio, puede hacerlo donde en el sitio GitHub dejaremos este código y el libro:
y los datos se pueden descargar de:
Hasta el siguiente post, y ya veremos métodos más óptimos para hacer este ejercicio.
Miguel Araujo.


Comentarios
Publicar un comentario