
En nuestro Instituto durante años se ha utilizado diversas herramientas para el procesamiento de información de acuerdo a las necesidades y también al expertise del personal.
En tiempos de austeridad republicana las herramientas de software libre sin duda tomarán más importancia en las áreas de estadística del Instituto y si agregamos que cuentan con la venía de nuestro emperador hemos empezado a transitar por este camino.
En su sitio oficial se define como "R es un software gratuito para cómputo estadístico y gráficos. Compila y se ejecuta en múltiples plataformas de UNIX, Windows y MacOS".
Llevo un par de cursos referentes a este lenguaje de programación que de hecho en la clasificación de los lenguajes en un principio era catalogado como funcional, ahora si revisamos Wikipedia aparece como multi-paradigma, aunque los principios de programación son los mismos tiene características muy especiales que intuyo vienen del calculo vectorial.
Como subdirección nos hemos dado a la tarea de hacer una serie de cuadros en la versión 3.5.2. La instalación nada de ciencia, y yo por comodidad estoy usando el R Studio un IDE para facilitar la programación.
Nuestro
buen subdirector tiene especial gusto por SQLite por lo que se usa
una librería paquete para poder usar las bases de datos de este
pequeño motor, así mismo se busca dejar los cuadros en formato
Excel y es por ello que se cargan un par de librerías para el acceso
a los libros, parece ser que estas librerías están soportadas por
la máquina virtual de Java entonces tenemos que referenciarla, por
último quien hace la magia y hace feliz al emperador es la librería
Survey que esta habilitada para generar los coeficientes de
variación, el error estándar y los límites superior e inferior, entre otras cosas.
Definitivamente
aunque tengas experiencia en desarrollo de sistemas es un lenguaje
diferente conforme pasan los días y avanzas en algunas ocasiones
buen trecho y otras veces te estancas, recuerdo bien lo que nos dijo
un instructor "En R todo es un arreglo".
Por
default R tiene su asistente gráfico llamado R Gui, como mencioné
nosotros usamos RStudio, IDE con versiones libres y de paga.
Lo
primero que tenemos que hacer es cargar las librerías, las cuales
mostraremos a continuación.
No todas las
librerías vienen con R por omisión, así que tenemos que instalar
los paquetes por lo que nos vamos a la opción Tools – Install
Packages

Luego en la ventana de dialogo anotamos el paquete a instalar:

Con estos pasos se descargarán los paquetes necesarios, y ahora si
nos ponemos a escribir el nuevo script de R.

El ejercicio que trataremos de replicar son cuadros de una encuesta
llamada ENADID 2014 (Encuesta Nacional de la Dinámica Demográfica).
Las
primeras 6 líneas se refieren a las librerías que utilizaremos para
trabajar con SQLite, Excel y lo necesario para realizar los cálculos.
La instrucción options es para fijar el número de
decimales que se desplegarán en las hojas de Excel. Sys.setenv es para
crear la variable de entorno JAVA_HOME y por último con setwd
fijamos un directorio de trabajo.

Encaminaremos
nuestros primeros esfuerzos en obtener las cifras expandidas del
cuadro 5.1, aquí observamos lo que se requiere para el cuadro.
Una
de las cosas que vamos aprendiendo es que si bien para sacar cifras
muestrales y expandidas se toma solo el subuniverso de la población,
en el caso de las precisiones se debe tomar TODO EL UNIVERSO para
obtener las mismas, por ello es que cuando extraemos el
conjunto de datos, la instrucción SQL no tiene ningún WHERE para
obtener los mismos.

La instrucción dbConnect() es
parte del paquete RSQLite, aquí creamos una conexión a la base de
datos ENADID2014.db (se tiene que hacer un proceso de conversión de
datos de FoxPro – formato que se encuentra en el sitio INEGI – a
una base de datos SQLite). Teniendo ya la conexión a la base de
datos podemos hacer un query (consulta) por medio de la instrucción
dbGetQuery()
extrayendo solo las variables que vamos a necesitar para generar el
cuadro. El resultado de esta
operación genera un objeto de tipo DataFrame de R, que es como un
arreglo con esteróides – jejeje, esto lo tomé cuando de un
artículo leí que Windows 7 era un XP con esteróides – es decir
una estructura de datos con nombres en las columnas.
Para este caso yo deseo hacer las variables del cuadro desde SQLite
(Select -When) y no en R, para empezar el grupo de edad, que es una
de las primeras variables de la fila. Revisando el FD tenemos una
variable llamada EDAD_1AG que se describe así:

En
el cuadro se puede observar que los primeros 5 grupos son
quinquenales, es decir abarcan 5 años, pero observamos que en el
último es un intérvalo de 10 años y por eso se recodifica
unificando los 9 y 10 de la variable.
La segunda variable de involucrada es el número
de hijos sobrevivientes
que lo denota la variable escalar P5_8,
también aquí se recodifica del 1 al 3, la tercera variable
involucrada es el
deseo de embarazarse P7_2 la
cual podemos codificar como 1,2 y 0, siendo cero los casos que
quedarían fuera del cuadro. Las demás variables se usan para el
cálculo de las precisiones y
algunas más que no son necesarias pero las trajimos por inercia.
En este query seguimos un método que nos ilustraron nuestros compañeros Tania Jazeth y Ernesto, así como Ricardo y Fernando, renombré las variables de grupo de edad (EDAD_1AG) por Fila1, el número de hijos sobrevivientes (P5_8) por Fila2 y la variable de la columna (P7_2) por Columna, así mismo la variable de mujer embarazada (P7_1) se renombró por Embarazo.
En este query seguimos un método que nos ilustraron nuestros compañeros Tania Jazeth y Ernesto, así como Ricardo y Fernando, renombré las variables de grupo de edad (EDAD_1AG) por Fila1, el número de hijos sobrevivientes (P5_8) por Fila2 y la variable de la columna (P7_2) por Columna, así mismo la variable de mujer embarazada (P7_1) se renombró por Embarazo.
Cuando
empezamos a caminar por esta jungla llamada R, es bueno ir dejando
huellas y analizándolas para entender que estamos haciendo en cada
una de ellas.
Si
queremos ejecutar parte del código simplemente lo seleccionamos y
damos clic en el botón Run
(o
Ctrl – Enter).

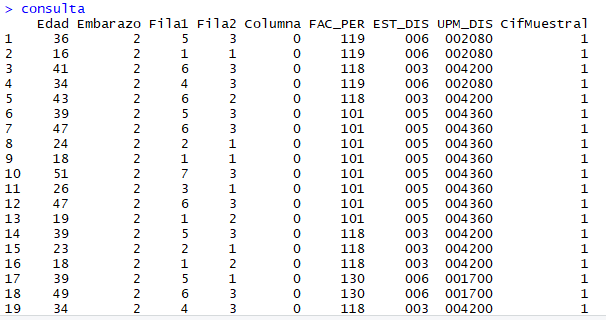
Y
para ver que obtuvimos, con dar consulta y Enter en la línea de
comandos checamos que contiene la variable.
Anteriormente
no éramos juez y parte, y una área de INEGI calculaba – y
entiendo que de todas formas lo tiene que hacer o al menos revisar –
les enviábamos las llamadas tablas/variables dicotómicas.
Siguiendo la misma lógica, calcularemos las variables dicotómicas
de la matriz principal.

Dichas celdas (variables dicotómicas) las he renombrado como si
fuera una matriz de 4x3, para definir si la celda tiene un 1 o un 0,
usamos la instrucción ifelse().
Para ejemplo podemos ver el total general donde le he puesto el
comentario #Universo.

Como
se trata de un sub-universo (subconjunto) que representa las mujeres
embarazadas (consulta$Embarazo=1) de 15 a 49 años (consulta$Fila1==1) estarán presentes en todo el cálculo
de variables dicotómicas, y luego las dos columnas sobre su deseo de
embarazarse o no (Columna=1 o 2).
Para después trabajar la matriz detalle de la siguiente variable de
fila (que le hemos nombrado Fila2).

Si nos damos cuenta con una simple asignación del tipo dataframe$nuevacolumna, se agregan columnas a este dataframe. A continuación vemos como luce el dataframe con nuevas columnas que son las variables dicotómicas.

Ahora algo que tenemos un poco confuso y oscuro las personas que
estudiamos las TIC’s y las materias de estadística nos pasaron de
noche, no las comprendimos del todo o no se vieron en la formación
académica. Definir el módelo estadístico.
DisenoE < - svydesign(id=~UPM_DIS, strata=~EST_DIS,
data=consulta, weights=~FAC_PER)
Podemos observar las variables que nos proporciona el área de marcos
estadísticos, así como el conjunto de datos que es el dataframe que
se ha construido.
La primera parte del cálculo nos brinda felicidad y un mucho de
optimismo, vamos a calcular el total de mujeres de 15 a 49 años que
están embarazadas, aplicamos uno de las funciones que nos da el
paquete survey, el svytotal() que nos da el
total de la variable dicotómica multiplicada por el factor y sumada
(la cifra expandida).
svytotal(~cel1_1,DisenoE)
total SE
cel1_1 1062455 24879
Aquí tenemos la cifra del total y su error estándar, y seguimos con
la felicidad de seguir calculando cifras de la primera línea del
cuadro, para ello en mi entender lo meto en un dataframe buscando
empatar el cuadro con las cifras que se están generando.
tablita <- cbind(data.frame(svytotal(~cel1_1,DisenoE)),
data.frame(svytotal(~cel1_2,DisenoE)),
data.frame(svytotal(~cel1_3,DisenoE))).
>tablita
total
|
cel1_1
|
total
|
cel1_2
|
total
|
cel1_3
|
|
| cel1_1 | 1062455
|
24879
|
675395
|
19405
|
386847
|
15230
|
Que podemos confrontar con las cifras del cuadro:

Todo
miel sobre hojuelas, sin embargo el tiempo apremia y mucho, entonces
¿hacer 84 celdas para un cuadro?, por más habilidad para el
copy-paste es demasiado código.
Tenemos otra función llamada svyby() la cifra a calcularse en
la variable dicotómica, y la cruzaremos por mi nuevo grupo de edad
buscando sacar en este pequeño ejemplo: “sin hijos
sobrevivientes por grupos de edad”. Aplicamos el svyby() con
la variable dicotómica cruzada con nuestra variable de grupos de
edad.
>subtotalcol1 < - svyby(~cel1_1, by=~Fila1, DisenoE,
svytotal)
>subtotalcol1
Fila1
|
cel1_1
|
SE
|
|
1
|
1
|
222728
|
11354
|
2
|
2
|
307741
|
13231
|
3
|
3
|
284611
|
13549
|
4
|
4
|
150695
|
8131
|
5
|
5
|
78850
|
7000
|
6
|
6
|
17830
|
3154
|
7
|
7
|
0
|
0
|

Ahora vamos con tres variables y aquí mi compañera Rosy Montoya me
mostró como se hacía esta magia usando R con el paquete survey
utilizando el símbolo + entre las 2 variables. Hablemos de “Un
hijo sobreviviente (cel3_1) por grupos de edad (Fila1)
y deseo de embarazarse (Columna)”
>detalle3_1 < - svyby(~cel3_1, by=~Fila1 + ~Columna,
DisenoE, svytotal)
>detall3_1
Fila1
|
Columna
|
cel3_1
|
Columna
|
|
1.0
|
1
|
0
|
0
|
0
|
2.0
|
2
|
0
|
0
|
0
|
3.0
|
3
|
0
|
0
|
0
|
4.0
|
4
|
0
|
0
|
0
|
5.0
|
5
|
0
|
0
|
0
|
6.0
|
6
|
0
|
0
|
0
|
7.0
|
7
|
0
|
0
|
0
|
1.1
|
1
|
1
|
15754
|
2955
|
2.1
|
2
|
1
|
70095
|
6331
|
3.1
|
3
|
1
|
85364
|
7299
|
4.1
|
4
|
1
|
42592
|
4389
|
5.1
|
5
|
1
|
17056
|
3684
|
6.1
|
6
|
1
|
3408
|
1306
|
7.1
|
7
|
1
|
0
|
0
|
1.2
|
1
|
2
|
21582
|
3918
|
2.2
|
2
|
2
|
40171
|
4153
|
2.3
|
3
|
2
|
24972
|
4165
|
2.4
|
4
|
2
|
8532
|
1684
|
2.5
|
5
|
2
|
1797
|
840
|
2.6
|
6
|
2
|
1052
|
941
|

Y listo por ahora tenemos el cuadro en pedacitos ahora lo interesante
es juntarlo y acomodar cada cifra en su lugar y aparte calcular los
porcentajes, el coeficiente de variación, el error estándar y los
límites superior e inferior.
Hasta aquí con esta entrega.
Miguel Araujo
Comentarios
Publicar un comentario