Ahora viene lo bueno y otra vez entramos a terrenos que dominan más
los matemáticos-estadísticos, aunque de hecho el cálculo pues no
es más que usar otra función del paquete survey y ya.
En la página del INEGI hay un artículo
llamado “Una aproximación metodológica al uso de datos de
encuestas en hogares” escrito por el ex-compañero Julio Cesar
Martínez Sánchez, donde menciona de forma llana y sencilla una
definición de estas mediciones.
“...existen algunas medidas de dispersión que son útiles
para evaluar la calidad de un dato que se genera a partir de una
encuesta compleja. Dentro de éstas se encuentran los errores
estándar y de muestreo, el intervalo de confianza y el coeficiente
de variación (Carsey, 2014; EUSTAT, 1998; Steven, 1999;
Naciones Unidas, 2009; Wolter, 2009). Esta última es de gran
importancia, pues refleja la magnitud relativa que tiene dicho error
estándar con respecto al estimador de referencia, y entre más
pequeño sea este valor, mejor es la precisión. Si bien no existe un
consenso unánime sobre qué valores son los más adecuados, el INEGI
considera que un dato es de buena calidad si el coeficiente de
variación está por debajo de 15%, aceptable si se encuentra entre
15 y 25% y de baja calidad cuando supera 25 por ciento.”
Entonces sin ahondar mucho en el tema estamos hablando de la calidad
del dato que se ha recolectado.
Entremos en materia. Vamos con el primer porcentaje o mejor dicho con
el dato absoluto de mujeres embarazadas de 15 a 49 años.
Quedamos que para obtener el dato total de personas de este
subuniverso es usando svytotal()
>total < - svytotal(~cel1_1, DisenoE)
Y aplicamos la función cv para el cálculo del
coeficiente de variación multiplicado por 100.
>cv(total)*100
cel1_1
cel1_1 2.34
El resultado es 2.34 como viene en el cuadro que se publicó, ahora
lo hacemos con el dato porcentual.
>porcel1_2 < - svyratio(~cel1_2, denominator=~cel1_1,
DisenoE)
>cv(porcel1_2)*100
cel1_1
cel1_2 1.76
Estos dos datos según el parámetro INEGI es un dato muy confiable,
ahora lo que queda es sacarlos masivamente y que esto será posible
usando el mismo patrón que he usado para la programación.

El código nuevamente construye las 3 columnas para al final
construir el cuarto dataframe.
>Cuadro5_1cv <- data.frame(col1, col2, col3)

Para la interpretación del cuadro se “colorean” las celdas para
mostrar el grado de confiabilidad, de blanco, amarillo y naranja de
mayor a menor calidad, incluso aquí se observa que para mujeres
embarazadas de 40 a 49 años que querían esperar o no deseaban
embarazarse (74.33) el dato se elimina de la publicación.
Vamos ahora con el error estándar nos referimos a un libro del censo
del año de 1990 en Puerto Rico que define al error estándar de esta
forma “El error estándar (SE, por sus siglas en inglés) de una
estimación de la muestra es la medida de la variación entre las
estimaciones de todas las muestras posibles y es por lo tanto una
medida de la precisión con la cual una estimación de una muestra
particular se aproxima al resultado promedio de todas las muestras
posibles”
De alguna manera sale de forma directa con lo que ahora hemos hecho,
cada cálculo con svytotal(), svyratio() o svyby() se calcula el
error estándar, y la forma de accesar es anteponiendo SE (Standard
Error) y el cálculo en específico entre paréntesis, aquí algunos
ejemplos.
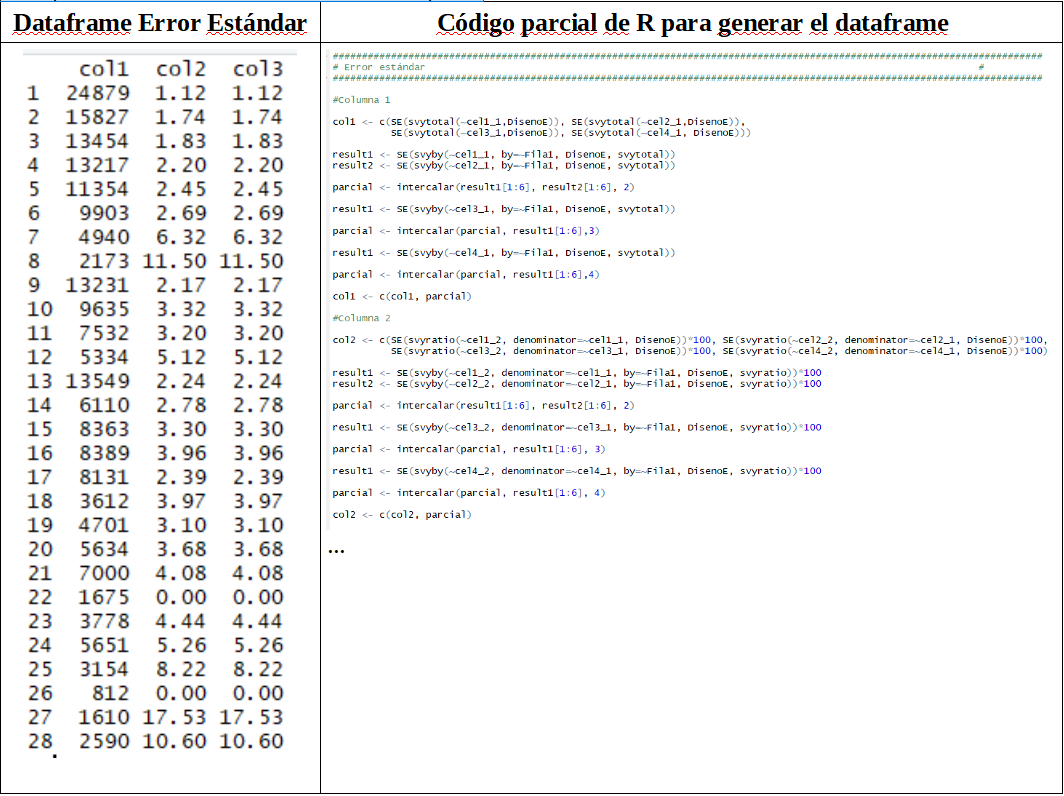
> SE(svytotal(~cel1_1, DisenoE))
cel1_1
cel1_1 24879
> SE(svyratio(~cel1_2, denominator=~cel1_1, DisenoE))*100
cel1_2/cel1_1
1.12
> SE(svyby(~cel1_2, denominator=~cel1_1,by=~Fila1,
DisenoE,svyratio))*100
[1] 2.45 2.17 2.24 2.39 4.08 8.22 NaN
> SE(svyby(~cel1_1, by=~Fila1, DisenoE, svytotal))
[1] 11354 13231 13549 8131 7000 3154 0

Para por último obtener el dataframe completo.
La conclusión a este documento lo hago ya cuando pude realizar 17
cuadros que me tocaron a desarrollar, y como anécdota diré que este
primer cuadro quedó 509 líneas (que sueño que te pagaran por línea
de código).
Cabe mencionar que falta la parte donde esta información se envía a
los cuadros de Excel para su edición final.
En los subsecuentes abordaré algunos aspectos finos de esta primer
experiencia de programación en R.
Miguel Araujo.
Comentarios
Publicar un comentario