Seguimos con esta serie de artículos que tiene el propósito de apoyar a personas que como yo inician en el mundo de R y de alguna manera a la ciencia de datos, así como para mi es una especie de cuaderno de notas digital.
El archivo con el que ejemplificó está en el sitio de INEGI y es la información de registros administrativos referentes a la estadística de mortalidad, en este caso específico para el año 2019.
Una gran amiga doctora, me consultó sobre como obtener causas de muerte de menores de edad con estos datos.
Una vez que descargamos el archivo lo que tenemos que hacer es crear el código en R para abrir este archivo en formato CSV usando Spark.
Para lo cual usamos las siguientes instrucciones:
library(sparklyr)
library(dplyr)
config <- spark_config()
config$`sparklyr.shell.driver-memory` <- "16G"
config$spark.memory.fractions <- 0.7
sc <- spark_connect(master="local", config = config)
defun19 <- spark_read_csv(sc, name = "defun19", path="D:/EjemplosR/defun19/conjunto_de_datos_defunciones_registradas_2019.CSV", delimiter=",", header = TRUE, overwrite = TRUE)
Esta nueva forma para configurar la conexión de Spark es para utilizar mejorar el uso de la memoria RAM [1], después se crea una conexión y se realiza una conexión con el archivo csv.
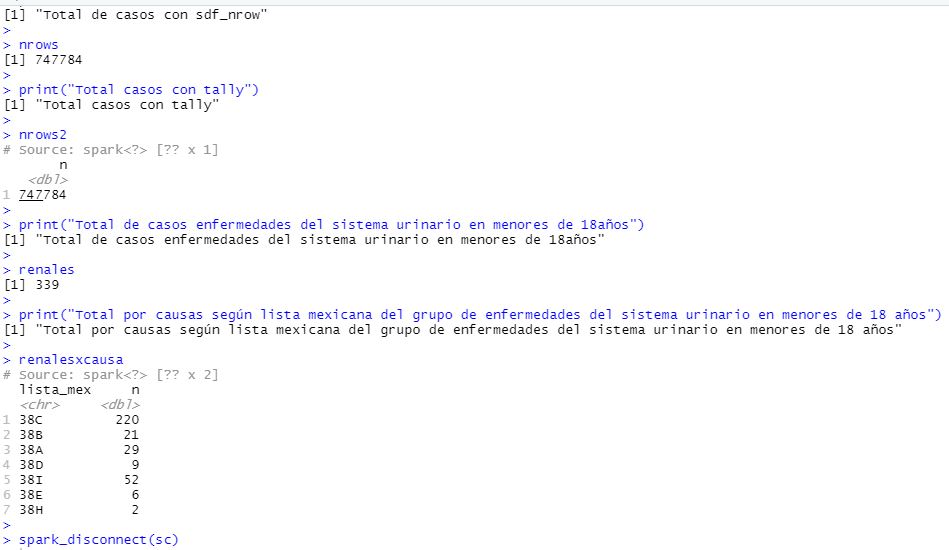
Cuando creía que las consultas con el paquete dplyr en R, las podía realizar usando de alguna manera haciendo similitudes con SQL y de acuerdo a lo que escribí en un artículo anterior, si para que me devuelva el número de filas/registros se resolvía con esta instrucción:
nrows <- defun19 %>% summarise(n())
Lo lógico era agregarle una condición con filter.
nrows2 <- defun19 %>% summarise(n()) %>% filter(lista_mex=="33B" | lista_mex=="33C")
Sin embargo al consultar la variable me marcó lo siguiente:

Encontré la verdad información muy escueta y en inglés sobre sdf_nrow (parece que es de Spark)[2] y tally() [3] que también parece ser nativo de R, pero funcionó y ambas de forma rápida.
Vamos con algo especifico; mi amiga es pediatra con especialidad en nefrología por lo que vamos a filtrar las defunciones del grupo de la lista mexicana 38 que es "enfermedades del sistema urinario" y menores de 18 años, por ahora queremos absolutos.
Los códigos de la lista mexicana se puede descargar aquí.
##Enfermedades del sistema urinario en menores de 18 años
renales <- defun19 %>% filter(trim(gr_lismex)=="38" & edad<4018) %>% sdf_nrow()

[1] Sparklyr from RStudio https://spark.rstudio.com/guides/connections/
[2] Sparklyr from RStudio https://spark.rstudio.com/reference/
[3] RDocumentation https://www.rdocumentation.org/packages/dplyr/versions/0.7.8/topics/tally#:~:text=tally()%20is%20a%20convenient,before%20and%20ungroup()%20after.
Comentarios
Publicar un comentario