“La importancia de no claudicar”.
Quizás en anteriores artículos he mencionado – quizás no – la buena y grata impresión que causó en nosotros, la gente de México, del Instituto, la actualización, para algunos y la presentación para otros del software REDATAM en el año 2003.
Nuestros compañeros de Chile durante varios días nos mostraron las bondades de este software y el curso en general recuerdo que tenía 2 vertientes, el enfoque desde el usuario y el enfoque desde el desarrollador.
Han pasado poco más de 17 años y entre pausas y olvidos en mi caso, la herramienta siempre me ha parecido muy propicia debido a las múltiples ventajas contra algunos inconvenientes que considero son salvables.
Antes de que se claudicara con la generación de las estadísticas de cultura procesamos unos 3 años de resultados utilizando REDATAM y en el pasado más inmediato lo usamos para los tabulados del módulo de CIBERACOSO así como algunas otras encuestas ya utilizando la versión 7.
En mi segundo intento con REDATAM publiqué algunos artículos cuando probé la nueva versión en la parte de CREATE para los formatos CSV, FoxPro y CSPro.
Sin embargo en mi anterior área aparte de generar resultados nos empezaron a pedir calcular las precisiones estadísticas y entre que los proyectos nos empezaron a asfixiar por el tiempo, la subdirección migró a R para este fin, quedando pendiente una charla – pregunta con Lenin Aguinaga sobre este tema.
Ahora y debido a un cambio laboral “he vuelto a casa” es decir a los registros administrativos donde ya no trabajamos con muestras sino con universos completos por lo que creo que REDATAM vuelve a ser otra muy buena opción, de hecho hay un antecedente en el cual mi compañero y mentor Pedro Reyna empezó a crear bases de datos REDATAM para las estadísticas vitales.

Grandes volúmenes de datos.
Una información que acaba de ser declarada como información de interés nacional son los puestos de trabajo registrados ante el Instituto Mexicano del Seguro Social que en el pasado año cerró 19,821,651 puestos de trabajo.
Dado que se da un seguimiento mensual, el archivo anual cerraría con unos 240 millones de registros a cifras actuales es por ello que en la dirección se trabaja con herramientas de “big compute” como lo es Spark que ha dado muy buenos resultados para realizar estas tareas.
En este panorama las herramientas como MS Excel y Visual FoxPro ya no son operables debido a que rebasa sus límites en los tamaños de los archivos.
Base de datos Oracle.
Una de las variantes ahora es utilizar una base de datos de Oracle debido a que el Instituto tiene licencias para este poderoso software, entonces se construyó una base de datos de Oracle para contener los puesto de trabajo del 2016 para hacer pruebas, el resultado fue una base de datos de un poco más de 220 millones de registros para ese año.
Una vez teniendo esta base de datos vi la conveniencia de crear la base de datos en REDATAM ya que años atrás mi compañero y exjefe Mario Becerril pudo subir la base de datos del Censo Nacional de Población y Vivienda del año 2010 con todo y los más 100 millones de residentes que se contabilizaron para ese evento, por lo que decidí poner a prueba a REDATAM con esta nueva estadística que si bien casi duplica el tamaño en registros, las columnas son muy pocas 8 para ser exactos.
Métodos de exportación de Oracle.
Aunque me gustaría hacer un apartado para hablar de este tema, para este caso trabajé con 2 métodos de exportación el gráfico que tiene SQL Developer y usando SQL*Plus con el comando SPOOL.
A diferencia de otros casos como la importación de archivos me parece que aquí el método gráfico es más rápido que usar SPOOL, aunque debido a un problema de configuración de monitores ya que estamos en tele-trabajo tuve que usar la consola de Oracle.
Primer intento Red7 Create– crear la base de datos con archivos CSV.
Debido a que nuestro Instituto se están popularizando los formatos de archivos de texto específicamente CSV (aunque el separador sea un padline (|)) empecé con REDATAM 7 usando como entrada del archivo el formato CSV.
Después de varios intentos el programa mandaba un error y al guardar y querer volver a entrar Red7 Create y abrir el archivo con extensión Wipx marcaba que estaba corrompido. Intente hacer la base de datos con un solo mes, pero tampoco tuve éxito.
Segundo intento Red7 Create – crear la base de datos con archivos de CSPro.
Debido a que una tabla de Visual FoxPro y desconozco si los archivos de SPSS soporten archivos tan grandes opté por hacer un diccionario de CSPro y su correspondiente archivo de datos después de todo es para datos censales por lo que pensé que no había problemas para cargar archivos de millones de registros.
Aquí parecía que íbamos a tener éxito sin embargo al llegar al 92% el programa abortaba sin mandar ningún mensaje, en este momento recurrí nuevamente a Lenin, preguntando sobre si ya no era posible manejar archivos tan grandes aunque yo seguía con esperanzas ahora yendo a la versión anterior de REDATAM que es la +SP.
Lenin me dijo que ese era el camino, el clásico “divide y vencerás”.
Tercer intento y el éxito.
Pusimos a trabajar un script de SQL para hacer 12 archivos que contienen los puestos de trabajo mes a mes, además que descargamos la versión de REDATAM +SP. Ya no intenté seguir con la versión nueva ya que con la anterior versión se había hecho la base de datos del Censo.
Lo primero fue crear el archivo ddf (Chillán) para poder construir nuestra jerarquía en base a este archivo, aquí un extracto del archivo ddf.

Ahora hacemos nuestro archivo wip que contiene la jerarquía del archivo y es con el cual sirve para generar nuestros archivos (base de datos) de REDATAM.

Ahora hicimos las 12 bases de datos para cada mes de los puestos de trabajo y se pudo hacer sin ningún problema.
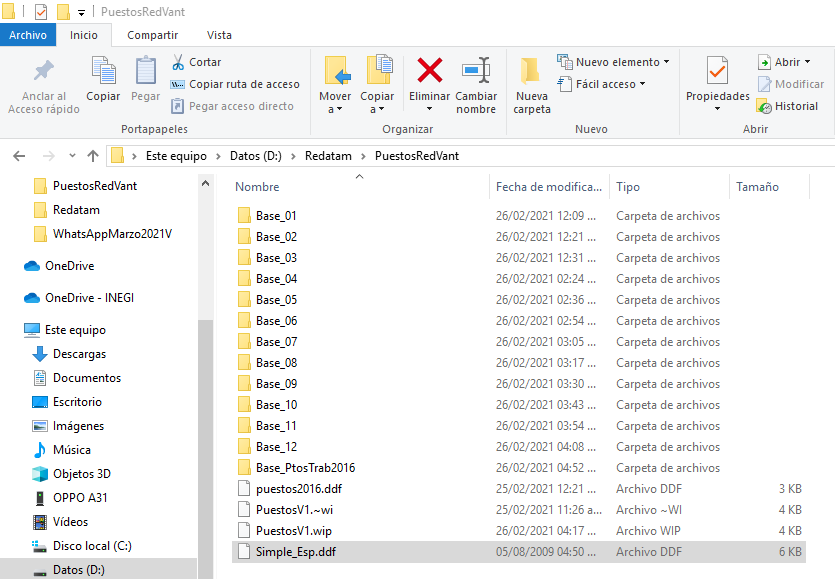
Esta versión en su componente Redatam +SP Process al igual que la nueva tiene una herramienta para “unir” bases de datos con la misma estructura, y es lo que procedimos a hacer.

Nos muestra una ventana donde ponemos las bases de datos que vamos a unir y se ejecuta dando clic en el botón de “Ejecutar”.
Quizás para darle emoción dejé el proceso corriendo pensando la volver que resultado tendría, para mi agrado y satisfacción la creación de la base de datos se realizó con éxito.
La verdad quedo nuevamente con un grato sabor de boca un cruce de dos variables (mes contra sexo) y aunque no compite con Oracle (aunque falta poner los leyendas y hacer el pivote) el tiempo en que se hizo fue de 2:07 minutos.

Entonces después de esto no puedo decir más que “¡ sos grande REDATAM !”
Hablaremos sobre esto en los siguientes artículos, nos seguimos leyendo.
Con grata satisfacción, me despido.
Miguel Araujo.
Comentarios
Publicar un comentario